pandas-numpy压缩保存数据
numpy的保存
https://numpy.org/doc/stable/reference/generated/numpy.save.html
numpy保存数组比较简单。
1 | # 1. 保存单个数组 |
pandas的保存
pandas保存复杂得多,提供了非常多的格式,常见的:csv,xlsx,h5等。
| Type | Data Description | Format | Reader | Writer |
|---|---|---|---|---|
| text | CSV | .csv | read_csv | to_csv |
| text | Fixed-Width Text File | .csv | read_fwf | NA |
| text | JSON | .json | read_json | to_json |
| text | HTML | .html | read_html | to_html |
| text | LaTeX | .tex | Styler.to_latex | NA |
| text | XML | .xml | read_xml | to_xml |
| text | Local clipboard | / | read_clipboard | to_clipboard |
| binary | MS Excel | .xlsx | read_excel | to_excel |
| binary | OpenDocument | .ods | read_excel | NA |
| binary | HDF5 Format | .hdf | read_hdf | to_hdf |
| binary | Feather Format | .feather | read_feather | to_feather |
| binary | Parquet Format | .parquet | read_parquet | to_parquet |
| binary | ORC Format | .orc | read_orc | to_orc |
| binary | Stata | .dta | read_stata | to_stata |
| binary | SAS | .sas7bdat | read_sas | NA |
| binary | SPSS | .sav | read_spss | NA |
| binary | Python Pickle Format | .pkl | read_pickle | to_pickle |
| SQL | SQL | / | read_sql | to_sql |
对比读写速度和文件体积
1 | # %% |
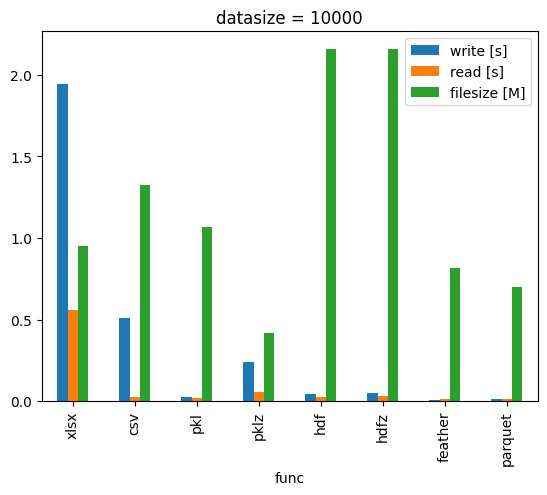
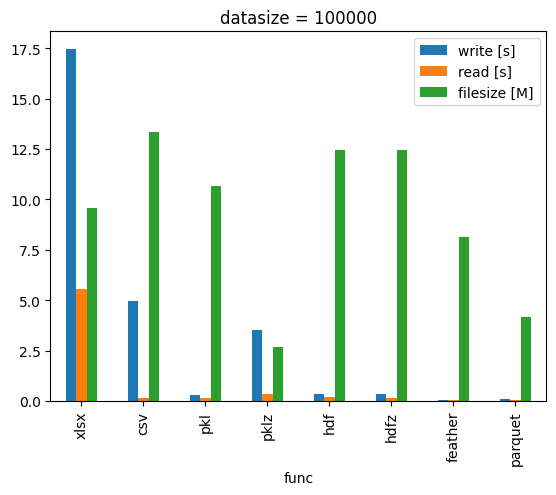
经过对比发现 feather 、 parquet 格式的压缩率、读写速度通常比其他格式更好一些。
feather、parquet 在vscode中的预览
这两种格式可以直接在VSCode中预览:
- feather :安装 Feather Viewer 插件;
- parquet :安装 Python Data Science (包含 Data Wrangler) 插件。